
TAGS
blog beats pixels code life datavisTOOLS
PythonNatural Language Toolkit (NLTK)
EchoNest Remix API
“Poetry becomes piano soliloquy — a beautiful mapping into the audio domain is possible, because Stein's unique linguistical algorithms created a corpus with self-similar structure.”
The result- A Picasso Soliloquy
Abstract
In this project I investigate a method of turning poetry into music, utilizing the unmistakeable words of Gertrude Stein. Poetry becomes piano soliloquy — a beautiful mapping into the audio domain is possible, because Stein’s unique linguistical algorithms created a corpus with self-similar structure.
Introduction
When I was living on Maui in 2002, a good friend exposed me to Gertrude Stein by reading me some of her work, and letting me read some of Stein’s poetry myself.
It was maddening.
I disliked it immensely and I truly thought my head would explode.
A few years later I bought the album Rhythm Science by Dj Spooky; one of the tracks contained samples of Gertrude Stein reading her poetry over some beautiful beats (track 5: ‘Zeta Reticulli/If I Told Him, A Completed Portrait of Picasso’).
Ooooooooooooooooooh.
Suddenly — in a flash — something clicked.
Hearing Stein herself recite her work, her nuanced rhythms and articulated cadences syncopated over a head-bobbin’ beat, expanded my enjoyment for her poetry instantly. I could finally hear how she was playing with the ebb and flow of her sentences as she ‘remixed’ her own phrases.
Thus began my fascination with visualizing her work so I could appreciate it even deeper…. thank you Megan, and thank you Paul!
The Poem
IF I TOLD HIM, A Completed Portrait of Picasso
by Gertrude Stein
The Process
The parser and music generator are written in Python, utilizing the Natural Language Toolkit for language analysis, and the EchoNest Remix API for MIDI output/generation.
The process that is utilized is rather straight-forward and is illustrated in the diagram below:

The Algorithm
The core question is: how do we map an arbitrary number of words in an input text (with a correspondingly arbitrary subset of unique words) into a fixed/limited output space (that of a piano’s range, 5-7 octaves).
This is, of course, a lossy process, in that information is lost during the mapping between domains. This is unavoidable given our human acoustics and the western scale, although one could certainly use micro-pitches to map all words uniquely. While I might investigate this approach in the future, it would create a song that would decidely not sound like something composed for the piano.
I decided early on not to map onto any scale, choosing rather to use the full chromatic range. Mapping onto a scale would introduce artificial ‘jumps’, and I wanted the intervals that were generated (and heard) to represent actual intervals between word occurrences.
The diagram below maps out the flow of the Picasso poem with the beginning word at the top left. The y-axis represents unique words, the x-axis represents total words, and the more a word is used the larger its node becomes:
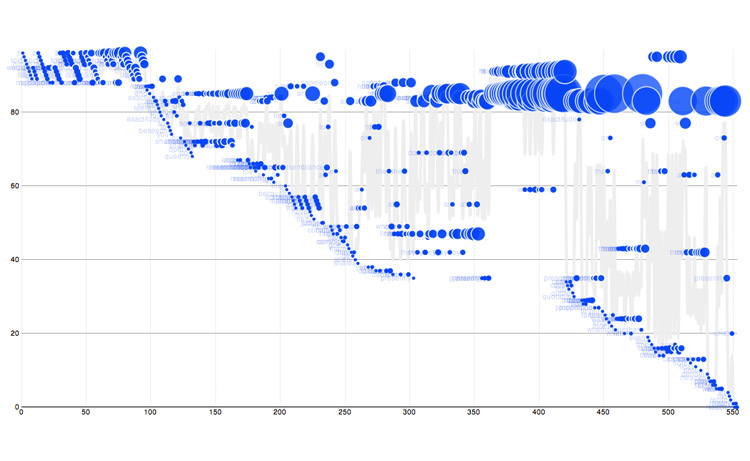
It is immediately apparent how she riffs on words and sentence fragments, and it is these patterns and repetitions that will translate into interesting music later.
(It might be useful to look at this visualization while listening to the rendered piano soliloquy; the beginning mappings will be more apparent than at the end.)
Every one of these words in the source text is processed and output as a note in the final song, each taking on distinct qualities as determined by a few major factors:
- The output note selection
- Loudness, lengths, pauses
- The tempo of the acoustic phrases
Note Selection
There are four variables that constrain the note selection:
- The desired output octave range (e.g. 4 octaves, C2-C6)
- The desired starting note within the output range (e.g. C4)
- The desired offset, or starting note of the output range (e.g. C2)
- The desired direction of travel (e.g. ‘down’)
A given word’s mapping is calculated first by determining its unique index (the index at which it first appears). This table illustrates the difference:
| Word | Absolute Index | Unique Index |
| If | 1 | 1 |
|---|---|---|
| I | 2 | 2 |
| told | 3 | 3 |
| him | 4 | 4 |
| would | 5 | 5 |
| he | 6 | 6 |
| like | 7 | 7 |
| it | 8 | 8 |
| would | 9 | 5 |
| he | 10 | 6 |
| like | 11 | 7 |
| it | 12 | 8 |
| if | 13 | 1 |
| I | 14 | 2 |
| told | 15 | 3 |
| him. | 16 | 4 |
| . | ||
| . | ||
| . | ||
| would | 20 | 5 |
| Napoleon | 21 | 21 |
It is worth commenting on this last value of 21 for Napoleon: I wanted to encode the length of time/space it took to get to the first occurrence of a word. If I had defined ‘unique word’ as the relative index, then Napoleon would have mapped to 9 (as it was the 9th unique word introduced), but I would have lost this time encoding. (Put another way: the longer it takes Stein to get to the first usage of Napoleon, the larger the jump will be.)
Now the note determination is a simple calculation:
offset + (startnote +/- unique_index) % range
where +/- is determined by the direction of the output flow.
Obviously the more unique words (and/or the longer the poem) the more overlap there will be in the word ➡ note mappings as the notes begin to wrap around the ‘edge’ of the output range and multiple words begin to map into the same note value.
Loudness, Lengths, Pauses
Sentences that end in periods, or contain commas, will result in a bit of pause in the melody, thereby encoding the sentence phrasing into the audio output.
As an extra ‘de-robotization’ method I inject micro-pauses throughout and shift the note outputs just slightly to sound more humanly produced.
Finally, the length of a note is proportional to the number of syllables in the word, and as a word is used more frequently it becomes louder and more emphasized.
Phrase Tempo
I encode sentences into melodic phrases containing their own tempo (varying only slightly from the overall average tempo) to give some discreet shaping to the segments.
The Result
The end soliloquy is a quasi-‘free-jazz’ piece containing the same self-similarity that the poem does, creating a remarkably listenable and enjoyable translation into musical notes. It is Stein’s unique method of sentence construction that creates the repetition and pattern-reuse that is invaluable when creating music.
I will be analyzing and visualizing Gertrude Stein’s linguistic constructions in Part Two.
In Part Three, I will post the github project, along with additional examples of soliloquies generated from Stein, as well as from Dr. Seuss, Shel Silverstein and others.

